Writing a hobby C Compiler
If I had six hours to chop down a tree, I'd spend the first four hours sharpening the axe - Abraham LincolnA few months ago a compiler might as well have been magic to me, I know high level languages and I know assembly, but the translation was a complete mystery. So I bought the Dragon book and read it cover to cover and wrote one, the whole process took about two months of reading/working through the book excercises in my lunchtimes and one month of developing it in my evenings. To break that down further the development time was roughly 1/3 planning, 1/3 writing, and 1/3 testing/debugging.
click here to skip to the code
This compiler isn't particularly complete, for example it's missing: increment/decrement operators, do{}while, and the '?' operator, and whilst this parses most of valid C, it then proceeds to ignores most of it. It also does no optimization and produces very inefficient code.
What I do parse is in accordance with the below finite state machine and the grammar here.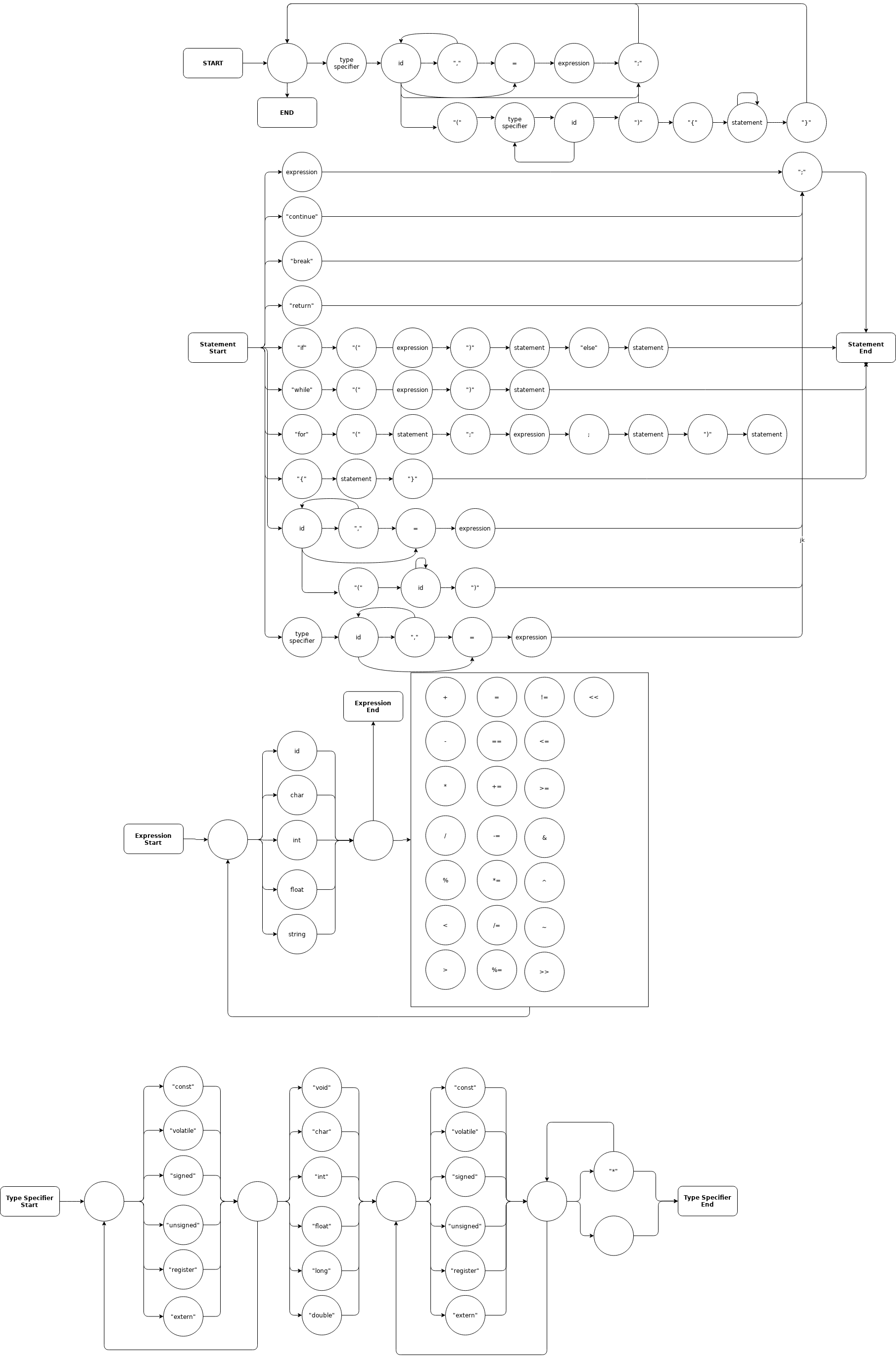
I mostly wanted put into action some of the theory from the Dragon book so whilst it's not feature complete, the main elements of a compiler are in place and working so it could be extended to support the rest. The largest valid C program I have is to generate the fibonacci sequence:
extern printf(const char *fmt, ...);
int c;
int main(){
int i = 10;
int a = 1;
int b = 1;
while(i){
i = i - 1;
c = a + b;
a = b;
b = c;
printf("%d\n",c);
}
return 0;
}
This compiles on OpenBSD 6.8 for AMD64 and requires nasm and ld.lld. The compiler targets NASM as it does a lot of the work for me meaning I don't have to do any backpatching.
>$ ./cc while.c >$ ./a.out 2 3 5 8 13 21 34 55 89 144 Segmentation fault (core dumped)
Faults
I've heard it said that your first compiler will be terrible, so thinking about this I saw the project as two compilers: from C to intermediate code, and from intermediate code to assembly language. Even this split was not enough to save me and I made plenty of bad decisions which I will now reflect on in order of how much trouble they caused me:Incrementing the parse tree node selector after returning
"return realterminal++;" was probably the worst statement I wrote, I didn't think it through and I quickly made a parse tree which is all broken, this alone makes me not want to continue with this compiler.
Generating intermediate code with the output directly from the lexar
The intermediate code grammar is designed so it is possible to read it straight from the lexical analyser, this makes it fast but horrible to add extra functionality for, this is the main reason I stopped developing the intermediate code->assembly translator.
parse tree nodes are joined by named variables in a structure as opposed to an array
This along with a bad design for multiple statements is very annoying to program and has resulted in a lot of unnecessary switch statements.
The emitter was written fairly late in the intermediate->asm process
The intermediate->assembly code was originally written as an interpreter using printf statements, I should have written an emitter much earlier. It would also make porting this to different architectures easier.
I mostly came up with the C->Intermediate translation scheme on the fly
This would have benefited from more planning and resulted in a messy implementation
Using a random number generator in place of a register allocator
This was done because it was the fastest register allocator I could think of to implement. I figured this might cause intermittent issues and it did, since printf clobbers some registers and I haven't perfectly accounted for it this causes the target program to only compile some and work some of the time
All output is done to files
This didn't have much thought put into it, it was mostly because it was quick and easy to implement. The main drawback is that it is difficult to make modifications to the resulting code. My nasty workaround for this is using grep at the end to move some elements to the data section.
This has been a very informative project and I've learnt a lot. The main takeaways where that the more time I spent planning an element the better that element turned out, and that a functioning compiler is very achievable for an individual to develop.